Процесс загрузки ядра. Часть 2.
Первые шаги в настройке ядра
Мы начали изучение внутренностей Linux в предыдущей части и увидели начальную часть кода настройки ядра. Мы остановились на вызове функции main (это первая функция, написанная на C) из arch/x86/boot/main.c.
В этой части мы продолжим исследовать код установки ядра, а именно
защищённый режим,- переход в него,
- инициализацию кучи и консоли,
- обнаружение памяти, проверку CPU, инициализацию клавиатуры
- и многое другое.
Итак, давайте начнём.
Защищённый режим
Прежде чем мы сможем перейти к нативному для Intel64 режиму Long Mode, ядро должно переключить CPU в защищённый режим.
Что такое защищённый режим? Защищённый режим был впервые добавлен в архитектуре x86 в 1982 году и был основным режимом процессоров Intel, начиная с 80286, пока в Intel64 не появился режим Long Mode.
Основная причина не использовать режим реальных адресов заключается в том, что возможен лишь очень ограниченный доступ к оперативной памяти. Как вы помните из предыдущей части, есть только 220 байт или 1 мегабайт, а иногда даже 640 килобайт оперативной памяти, доступной в режиме реальных адресов.
Защищённый режим принёс много изменений, но главным является отличие в управлении памятью. 20-битная адресная шина была заменена на 32-битную. Это позволило обеспечить доступ к 4 Гб памяти против 1 мегабайта в режиме реальных адресов. Также была добавлена поддержка страничной организации памяти, про которую вы можете прочитать в следующих разделах.
Управление памятью в защищённом режиме разделяется на две, почти независимые части:
- Сегментация
- Страничная организация
Здесь мы будем говорить только о сегментации. Страничная организация будет обсуждаться в следующих разделах.
Как вы можете помнить из предыдущей части, адреса в режиме реальных адресов состоят из двух частей:
- Базовый адрес сегмента
- Смещение от базового сегмента
И мы можем получить физический адрес, если нам известны эти две части:
Физический адрес = Селектор сегмента * 16 + Смещение
Сегментация памяти в защищённом режиме была полностью переделана. В нём нет фиксированных 64 килобайтных сегментов. Вместо этого, размер и расположение каждого сегмента описывается структурой данных, называемой дескриптором сегмента. Дескрипторы сегментов хранятся в структуре данных под названием глобальная дескрипторная таблица (GDT).
GDT представляет собой структуру, которая находится в памяти. Она не имеет постоянного места в памяти, поэтому её адрес хранится в специальном регистре GDTR. Позже мы увидим загрузку GDT в коде ядра Linux. Там будет операция для её загрузки в память, что-то вроде:
lgdt gdt
где инструкция lgdt загружает базовый адрес и предел (размер) глобальной дескрипторной таблицы в регистр GDTR. GDTR является 48-битным регистром и состоит из двух частей:
- размер (16 бит) глобальной дескрипторной таблицы;
- адрес (32 бита) глобальной дескрипторной таблицы.
Как упоминалось ранее, GDT содержит дескрипторы сегментов, которые описывают сегменты памяти. Каждый дескриптор является 64-битным. Общая схема дескриптора такова:
63 56 51 48 45 39 32
-------------------------------------------------------------------------------
| | |B| |A| | | | |0|E|W|A| |
| БАЗОВЫЙ АДРЕС 31:24 |G|/|L|V| ПРЕДЕЛ |P|DPL|S| ТИП | БАЗОВЫЙ АДРЕС 23:16 |
| | |D| |L| 19:16 | | | |1|C|R|A| |
-------------------------------------------------------------------------------
31 16 15 0
-------------------------------------------------------------------------------
| | |
| БАЗОВЫЙ АДРЕС 15:0 | ПРЕДЕЛ 15:0 |
| | |
-------------------------------------------------------------------------------
Не волнуйтесь, я знаю, после режима реальных адресов это выглядит немного страшно, но на самом деле всё довольно легко. Например, ПРЕДЕЛ 15:0 означает, что биты 0-15 предела расположены в начале дескриптора. Остальная часть находится в ПРЕДЕЛ 19:16, который расположен в битах 48-51 дескриптора. Таким образом, размер предела составляет 0-19, т.е 20 бит. Давайте внимательно взглянем на структуру дескриптора:
Предел (20 бит) находится в пределах 0-15, 48-51 бит. Он определяет
длину_сегмента - 1. Зависит от битаG(гранулярность).- Если
G(бит 55) и предел сегмента равен 0, то размер сегмента составляет 1 байт - Если
Gравен 1, а предел сегмента равен 0, то размер сегмента составляет 4096 байт - Если
Gравен 0, а предел сегмента равен 0xfffff, то размер сегмента составляет 1 мегабайт - Если
Gравен 1, а предел сегмента равен 0xfffff, то размер сегмента составляет 4 гигабайта
Таким образом, если
- G равен 0, предел интерпретируется в терминах 1 байта, а максимальный размер сегмента может составлять 1 мегабайт.
- G равен 1, предел интерпретируется в терминах 4096 байт = 4 килобайта = 1 страница, а максимальный размер сегмента может составлять 4 гигабайта. На самом деле, когда G равен 1, значение предела сдвигается на 12 бит влево. Таким образом, 20 бит + 12 бит = 32 бита и 232 = 4 гигабайта.
- Если
Базовый адрес (32 бита) находится в пределах 16-31, 32-39 и 56-63 бит. Он определяет физический адрес начального расположения сегмента.
Тип/Атрибут (5 бит) в пределах 40-47 бит определяет тип сегмента и виды доступа к нему.
- Флаг
S(бит 44) определяет тип дескриптора. ЕслиSравен 0, то этот сегмент является системным сегментом, а еслиSравен 1, то этот сегмент является сегментом кода или сегментом данных (сегменты стека являются сегментами данных, которые должны быть сегментами для чтения/записи).
- Флаг
Для того чтобы определить, является ли сегмент сегментом кода или сегментом данных, мы можем проверить атрибут (бит 43), обозначенный как 0 в приведённой выше схеме. Если он равен 0, то сегмент является сегментом данных, в противном случае это сегмент кода.
Сегмент может быть одного из следующих типов:
| Поле типа | Тип дескриптора | Описание
|-----------------------------|-----------------|------------------
| Десятичное | |
| 0 E W A | |
| 0 0 0 0 0 | Данные | Только для чтения
| 1 0 0 0 1 | Данные | Только для чтения, было обращение
| 2 0 0 1 0 | Данные | Чтение/запись
| 3 0 0 1 1 | Данные | Чтение/запись, было обращение
| 4 0 1 0 0 | Данные | Только для чтения, растёт вниз
| 5 0 1 0 1 | Данные | Только для чтения, растёт вниз, было обращение
| 6 0 1 1 0 | Данные | Чтение/запись, растёт вниз
| 7 0 1 1 1 | Данные | Чтение/запись, растёт вниз, было обращение
| C R A | |
| 8 1 0 0 0 | Код | Только для выполнения
| 9 1 0 0 1 | Код | Только для выполнения, было обращение
| 10 1 0 1 0 | Код | Выполнение/чтение
| 11 1 0 1 1 | Код | Выполнение/чтение, было обращение
| 12 1 1 0 0 | Код | Только для выполнения, подчинённый
| 14 1 1 0 1 | Код | Только для выполнения, подчинённый, было обращение
| 13 1 1 1 0 | Код | Выполнение/чтение, подчинённый
| 15 1 1 1 1 | Код | Выполнение/чтение, подчинённый, было обращение
Как мы можем видеть, первый бит (бит 43) равен 0 для сегмента данных и 1 для сегмента кода. Следующие три бита (40, 41, 42): либо биты EWA (бит направления расширения (Expansion), бит записи (Writable), бит обращения (Accessible)), либо CRA (бит подчинения (Conforming), бит чтения (Readable), бит доступа (Accessible)).
- Если E (бит 42) равен 0, то сегмент растёт вверх, в противном случае растёт вниз. Подробнее здесь.
- Если W (бит 41) (для сегмента данных) равен 1, то запись в сегмент разрешена. Обратите внимание, что право на чтение всегда разрешено для сегментов данных.
- A (бит 40) - было ли обращение процессора к сегменту.
- C (бит 43) - бит подчинения (для сегмента кода). Если C равен 1, то сегмент кода может быть выполнен из более низкого уровня привилегий, например, из уровня пользователя. Если C равно 0, то сегмент может быть выполнен только из того же уровня привилегий.
- R (бит 41) контролирует доступ чтения сегментам кода; когда он равен 1, то чтение сегмента разрешено. Право на запись всегда запрещено для сегмента кода.
DPL [2 бита] (уровень привилегий сегмента (Descriptor Privilege Level)) находится в 45-46 битах. Определяет уровень привилегий сегмента от 0 до 3, где 0 является самым привилегированным.
Флаг P (бит 47) - указывает на присутствие сегмента в памяти. Если P равен 0, то сегмент является недействительным и процессор откажется читать этот сегмент.
Флаг AVL (бит 52) - доступный и зарезервированный бит. Игнорируется в Linux.
Флаг L (бит 53) - указывает на то, содержит ли сегмент кода нативный 64-битный код. Если он равен 1, то сегмент кода будет выполнен в 64-битном режиме.
Флаг D/B (бит 54) - флаг разрядности (Default/Big), определяет размер операнда, т.е 16/32 бит. Если он установлен, то находящиеся в сегменте операнды считаются имеющими размер 32 бита, иначе 16 бит.
Сегментные регистры содержат селекторы сегментов, так же как и в режиме реальных адресов. Тем не менее, в защищённом режиме селектор сегмента обрабатывается иначе. Каждый дескриптор сегмента имеет соответствующий селектор сегмента, который представляет собой 16-битную структуру:
15 3 2 1 0
-----------------------------
| Index | TI | RPL |
-----------------------------
Где,
- Index определяет номер дескриптора в GDT.
- TI (указатель таблицы (Table Indicator)) определяет таблицу, в которой нужно искать дескриптор. Если он равен 0, то поиск происходит в глобальной дескрипторной таблице (GDT), в противном случае в локальной дескрипторной таблице (LDT).
- RPL определяет уровень привилегий.
Каждый сегментный регистр имеет видимую и скрытую часть.
- Видимая - здесь хранится селектор сегмента.
- Скрытая - здесь хранится дескриптор сегмента, который содержит базовый адрес, предел, атрибуты, флаги.
Необходимы следующие шаги, чтобы получить физический адрес в защищённом режиме:
- Селектор сегмента должен быть загружен в один из сегментных регистров
- CPU пытается найти дескриптор сегмента по адресу
GDT + Indexиз селектора и загрузить дескриптор в скрытую часть сегментного регистра - Если страничная организация памяти отключена, линейный адрес сегмента или его физический адрес задается формулой: Базовый адрес (найденный в дескрипторе, полученном на предыдущем шаге) + Смещение.
Схематично это будет выглядеть следующим образом:
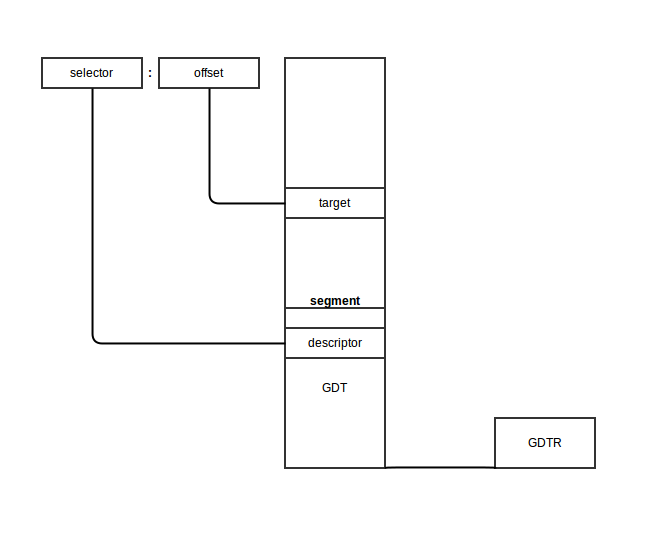
Алгоритм перехода из режима реальных адресов в защищённый режим:
- Отключить прерывания
- Описать и загрузить GDT инструкцией
lgdt - Установить бит PE (Protection Enable) в CR0 (регистр управления 0 (Control Register 0))
- Перейти к коду защищённого режима
Полный переход в защищённый режим мы увидим в следующей части, но прежде чем мы сможем перейти в защищённый режим, нужно совершить ещё несколько приготовлений.
Давайте посмотрим на arch/x86/boot/main.c. Мы можем видеть некоторые подпрограммы, которые выполняют инициализацию клавиатуры, инициализацию кучи и т.д. Рассмотрим их.
Копирование параметров загрузки в "нулевую страницу" (zeropage)
Мы стартуем из подпрограммы main в "main.c". Первая функция, которая вызывается в main - copy_boot_params(void). Она копирует заголовок настройки ядра в поле структуры boot_params, которая определена в arch/x86/include/uapi/asm/bootparam.h.
Структура boot_params содержит поле struct setup_header hdr. Эта структура содержит те же поля, что и в протоколе загрузки Linux и заполняется загрузчиком, а так же во время компиляции/сборки ядра. copy_boot_params делает две вещи:
Копирует
hdrиз header.S в полеsetup_headerв структуреboot_paramsОбновляет указатель на командную строку ядра, если ядро было загружено со старым протоколом командной строки.
Обратите внимание на то, что он копирует hdr с помощью функции memcpy, которая определена в copy.S. Взглянем на неё:
GLOBAL(memcpy)
pushw %si
pushw %di
movw %ax, %di
movw %dx, %si
pushw %cx
shrw $2, %cx
rep; movsl
popw %cx
andw $3, %cx
rep; movsb
popw %di
popw %si
retl
ENDPROC(memcpy)
Да, мы только что перешли в C-код и снова вернулись к ассемблеру :) Прежде всего мы видим, что memcpy и другие подпрограммы, расположенные здесь, начинаются и заканчиваются двумя макросами: GLOBAL и ENDPROC. Макрос GLOBAL описан в arch/x86/include/asm/linkage.h и определяет директиву globl, а так же метку для него. ENDPROC описан в include/linux/linkage.h; отмечает символ name в качестве имени функции и заканчивается размером символа name.
Реализация memcpy достаточно проста. Во-первых, она помещает значения регистров si и di в стек для их сохранения, так как они будут меняться в течении работы. Как мы видим из REALMODE_CFLAGS в arch/x86/Makefile система сборки ядра использует параметр GCC -mregparm = 3, поэтому функции получают первые три параметра из регистров ax, dx и cx. Вызов memcpy выглядит следующим образом:
memcpy(&boot_params.hdr, &hdr, sizeof hdr);
Так,
axбудет содержать адресboot_params.hdrdxбудет содержать адресhdrcxбудет содержать размерhdrв байтах.
memcpy помещает адрес boot_params.hdr в di и сохраняет размер в стеке. После этого она сдвигается вправо на 2 размера (или делит на 4) и копирует из si в di по 4 байта. Далее снова восстанавливает размер hdr, выравнивает по 4 байта и копирует остальную часть байтов из si в di побайтово (если они есть). В конце восстанавливает значения si и di из стека и после этого завершает копирование.
Инициализация консоли
После того как hdr скопирован в boot_params.hdr, следующим шагом является инициализация консоли с помощью вызова функции console_init, определённой в arch/x86/boot/early_serial_console.c.
Функция пытается найти опцию earlyprintk в командной строке и, если поиск завершился успехом, парсит адрес порта, скорость передачи данных и инициализирует последовательный порт. Значение опции earlyprintk может быть одним из следующих:
- serial,0x3f8,115200
- serial,ttyS0,115200
- ttyS0,115200
После инициализации последовательного порта мы можем увидеть первый вывод:
if (cmdline_find_option_bool("debug"))
puts("early console in setup code\n");
Определение puts находится в tty.c. Как мы видим, она печатает символ за символом в цикле, вызывая функцию putchar. Давайте посмотрим на реализацию putchar:
void __attribute__((section(".inittext"))) putchar(int ch)
{
if (ch == '\n')
putchar('\r');
bios_putchar(ch);
if (early_serial_base != 0)
serial_putchar(ch);
}
__attribute__((section(".inittext"))) означает, что код будет находиться в секции .inittext. Мы можем найти его в файле компоновщика setup.ld.
Прежде всего, putchar проверяет наличие символа \n и, если он найден, печатает перед ним \r. После этого она выводит символ на экране VGA, вызвав BIOS с прерыванием 0x10:
static void __attribute__((section(".inittext"))) bios_putchar(int ch)
{
struct biosregs ireg;
initregs(&ireg);
ireg.bx = 0x0007;
ireg.cx = 0x0001;
ireg.ah = 0x0e;
ireg.al = ch;
intcall(0x10, &ireg, NULL);
}
initregs принимает структуру biosregs и в первую очередь заполняет biosregs нулями, используя функцию memset, а затем заполняет его значениями регистров:
memset(reg, 0, sizeof *reg);
reg->eflags |= X86_EFLAGS_CF;
reg->ds = ds();
reg->es = ds();
reg->fs = fs();
reg->gs = gs();
Давайте посмотри на реализацию memset:
GLOBAL(memset)
pushw %di
movw %ax, %di
movzbl %dl, %eax
imull $0x01010101,%eax
pushw %cx
shrw $2, %cx
rep; stosl
popw %cx
andw $3, %cx
rep; stosb
popw %di
retl
ENDPROC(memset)
Как мы можем видеть, memset использует тоже самое соглашение о вызовах, как и memcpy: это означает, что функция получает свои параметры из регистров ax, dx и cx.
Как правило, реализация memset подобна реализации memcpy. Она сохраняет значение регистра di в стеке и помещает значение ax в di, которое является адресом структуры biosregs. Далее идёт инструкция movzbl, которая копирует значение dl в младший байт регистра eax. Оставшиеся 3 верхних байта eax будут заполнены нулями.
Следующая инструкция умножает eax на 0x01010101. Это необходимо, так как memset будет копировать 4 байта одновременно. Например, нам нужно заполнить структуру, размер которой составляет 4 байта, значением 0x7 с помощью memset. В этом случае eax будет содержать значение 0x00000007. Так что если мы умножим eax на 0x01010101, мы получим 0x07070707 и теперь мы можем скопировать эти 4 байта в структуру. memset использует инструкцию rep; stosl для копирования eax в es:di.
Остальная часть memset делает почти то же самое, что и memcpy.
После того как структура biosregs заполнена с помощью memset, bios_putchar вызывает прерывание 0x10 для вывода символа. Затем она проверяет, инициализирован ли последовательный порт, и в случае если он инициализирован, записывает в него символ с помощью инструкций serial_putchar и inb/outb.
Инициализация кучи
После подготовки стека и BSS в header.S (смотрите предыдущую часть), ядро должно инициализировать кучу с помощью функции init_heap.
В первую очередь init_heap проверяет флаг CAN_USE_HEAP в loadflags в заголовке настройки ядра и если флаг был установлен, вычисляет конец стека:
char *stack_end;
if (boot_params.hdr.loadflags & CAN_USE_HEAP) {
asm("leal %P1(%%esp),%0"
: "=r" (stack_end) : "i" (-STACK_SIZE));
другими словами stack_end = esp - STACK_SIZE.
Затем идёт расчёт heap_end:
heap_end = (char *)((size_t)boot_params.hdr.heap_end_ptr + 0x200);
что означает heap_end_ptr или _end + 512(0x200h). Последняя проверка заключается в сравнении heap_end и stack_end. Если heap_end больше stack_end, то присваиваем stack_end значение heap_end, чтобы сделать их равными.
Теперь куча инициализирована и мы можем использовать её с помощью метода GET_HEAP. В следующих постах мы увидим как она используется, как её использовать и как она реализована.
Проверка CPU
Следующим шагом является проверка CPU с помощью функции validate_cpu из arch/x86/boot/cpu.c.
Она вызывает функцию check_cpu и передаёт ей два параметра: уровень CPU и необходимый уровень CPU; check_cpu проверяет, запущено ли ядро на нужном уровне CPU.
check_cpu(&cpu_level, &req_level, &err_flags);
if (cpu_level < req_level) {
...
return -1;
}
check_cpu проверяет флаги CPU, наличие long mode в случае x86_64 (64-битного) CPU, проверяет поставщика процессора и делает специальные подготовки для некоторых производителей, такие как отключение SSE+SSE2 для AMD в случае их отсутствия и т.д.
На следующем этапе вы видим вызов функции set_bios_mode. Эта функция реализована только для режима x86_64:
static void set_bios_mode(void)
{
#ifdef CONFIG_X86_64
struct biosregs ireg;
initregs(&ireg);
ireg.ax = 0xec00;
ireg.bx = 2;
intcall(0x15, &ireg, NULL);
#endif
}
Функция set_bios_mode выполняет прерывание 0x15, чтобы сообщить BIOS, что будет использоваться long mode (если bx == 2).
Обнаружение памяти
Следующим шагом является обнаружение памяти с помощью функции detect_memory. detect_memory в основном предоставляет карту доступной оперативной памяти для CPU. Она использует различные программные интерфейсы для обнаружения памяти, такие как 0xe820, 0xe801 и 0x88. Здесь мы будем рассматривать только реализацию 0xE820.
Давайте посмотрим на реализацию фуцнкции detect_memory_e820 в arch/x86/boot/memory.c. Прежде всего, функция detect_memory_e820 инициализирует структуру biosregs, как мы видели выше, и заполняет регистры специальными значениями для вызова 0xe820:
initregs(&ireg);
ireg.ax = 0xe820;
ireg.cx = sizeof buf;
ireg.edx = SMAP;
ireg.di = (size_t)&buf;
axсодержит номер функции (в нашем случае 0xe820)cxсодержит размер буфера, который будет содержать данные о памятиedxдолжен содержать магическое числоSMAPes:diдолжен содержать адрес буфера, который будет содержать данные из памятиebxдолжен быть равен нулю.
Далее идёт цикл, в котором будут собраны данные о памяти. Он начинается с вызова BIOS прерывания 0x15, который записывает одну строку из таблицы распределения адресов. Для получения следующей строки мы должны снова вызвать это прерывание (что мы и делаем в цикле). До следующего вызова ebx должен содержать значение, возвращённое ранее:
intcall(0x15, &ireg, &oreg);
ireg.ebx = oreg.ebx;
В конечном счёте мы делаем итерации в цикле для сбора данных из таблицы распределения адресов и записываем эти данные в массив e820entry:
- начало сегмента памяти
- размер сегмента памяти
- тип сегмента памяти (может ли конкретный сегмент быть использован или он зарезервирован).
Вы можете увидеть результат в выводе dmesg, что-то вроде:
[ 0.000000] e820: BIOS-provided physical RAM map:
[ 0.000000] BIOS-e820: [mem 0x0000000000000000-0x000000000009fbff] usable
[ 0.000000] BIOS-e820: [mem 0x000000000009fc00-0x000000000009ffff] reserved
[ 0.000000] BIOS-e820: [mem 0x00000000000f0000-0x00000000000fffff] reserved
[ 0.000000] BIOS-e820: [mem 0x0000000000100000-0x000000003ffdffff] usable
[ 0.000000] BIOS-e820: [mem 0x000000003ffe0000-0x000000003fffffff] reserved
[ 0.000000] BIOS-e820: [mem 0x00000000fffc0000-0x00000000ffffffff] reserved
Инициализация клавиатуры
Следующим шагом является инициализация клавиатуры с помощью вызова функции keyboard_init(). Вначале keyboard_init инициализирует регистры с помощью функции initregs. Затем он вызывает прерывание 0x16 для получения статуса клавиатуры.
initregs(&ireg);
ireg.ah = 0x02; /* Получение статуса клавиатуры */
intcall(0x16, &ireg, &oreg);
boot_params.kbd_status = oreg.al;
После этого она ещё раз вызывает 0x16 для установки частоты повторения и задержки.
ireg.ax = 0x0305; /* Установка частоты повторения клавиатуры */
intcall(0x16, &ireg, NULL);
Выполнение запросов
Следующие несколько шагов - запросы для различных параметров. Мы не будем погружаться в подробности этих запросов, но вернёмся к этому в последующих частях. Давайте коротко взглянем на эти функции:
Первым шагом является получение информации Intel SpeedStep с помощью вызова функции query_ist. Она проверяет уровень CPU, и если он верный, вызывает прерывание 0x15 для получения информации и сохраняет результат в boot_params.
Следующая функция - query_apm_bios получает из BIOS информацию об Advanced Power Management. query_apm_bios также вызывает BIOS прерывание 0x15, но с ah = 0x53 для проверки поддержки APM. После выполнения 0x15, функция query_apm_bios проверяет сигнатуру PM (она должна быть равна 0x504d), флаг переноса (он должен быть равен 0, если есть поддержка APM) и значение регистра cx (оно должено быть равным 0x02, если имеется поддержка защищённого режима).
Далее она снова вызывает 0x15, но с ax = 0x5304 для отсоединения от интерфейса APM и подключению к интерфейсу 32-битного защищённого режима. В итоге она заполняет boot_params.apm_bios_info значениями, полученными из BIOS.
Обратите внимание: query_apm_bios будет выполняться только в том случае, если в конфигурационном файле установлен флаг времени компиляции CONFIG_APM или CONFIG_APM_MODULE:
#if defined(CONFIG_APM) || defined(CONFIG_APM_MODULE)
query_apm_bios();
#endif
Последняя функция - query_edd, запрашивает из BIOS информацию об Enhanced Disk Drive. Давайте взглянем на реализацию query_edd.
В первую очередь она читает опцию edd из командной строки ядра и если она установлена в off, то query_edd завершает свою работу.
Если EDD включён, query_edd сканирует поддерживаемые BIOS жёсткие диски и запрашивает информацию о EDD в следующем цикле:
for (devno = 0x80; devno < 0x80+EDD_MBR_SIG_MAX; devno++) {
if (!get_edd_info(devno, &ei) && boot_params.eddbuf_entries < EDDMAXNR) {
memcpy(edp, &ei, sizeof ei);
edp++;
boot_params.eddbuf_entries++;
}
...
...
...
}
где 0x80 - первый жёсткий диск, а значение макроса EDD_MBR_SIG_MAX равно 16. Она собирает данные в массив структур edd_info. get_edd_info проверяет наличие EDD путём вызова прерывания 0x13 с ah = 0x41 и если EDD присутствует, get_edd_info снова вызывает 0x13, но с ah = 0x48 и si, содержащим адрес буфера, где будет храниться информация о EDD.
Заключение
Это конец второй части о внутренностях ядра Linux. В следующей части мы увидим настройки режима видео и остальные подготовки перед переходом в защищённый режим и непосредственно переход в него.
От переводчика: пожалуйста, имейте в виду, что английский - не мой родной язык, и я очень извиняюсь за возможные неудобства. Если вы найдёте какие-либо ошибки или неточности в переводе, пожалуйста, пришлите pull request в linux-insides-ru.
Ссылки
- Защищённый режим (Википедия)
- Защищённый режим (OSDEV)
- Long mode
- Неплохое объяснение режимов CPU с кодом
- Как использовать сегменты с ростом вниз на CPU Intel 386 и более поздних
- Документация по earlyprintk
- Параметры ядра
- Последовательная консоль
- Intel SpeedStep
- APM
- Спецификация EDD
- Документация TLDP для процесса загрузки Linux (старая)
- Предыдущая часть